GA4でCV分析をしていると、「数字は見えるのに、説明できない」場面が出てきます。
原因はシンプルで、CVを“点”で見ていて、CVに至るまでの“過程”が見えていないからです。
この記事では、GA4のBigQuery Exportを使って、初回セッションから最初のCVまでの行動を、セッション単位・時系列で可視化するSQLを紹介します。
媒体評価や改善判断を「感覚」から「構造」に寄せたい人向けの内容です。
Contents
GA4のCV分析で起きがちな「見えない問題」
GA4の標準レポートや普段の集計で見えているのは、どうしても「結果」の側です。
そのため、次のような“見えない問題”が起きやすくなります。
- ファースト接触とCV接触が違うのに、どちらを評価すべきか決められない
- CVは増減しているのに、なぜ増えた(減った)のか説明が弱い
- 「CVまで◯日」は見えても、その間に何回接触していたか、どんな流入だったかが曖昧
- 施策の良し悪しが、最後に踏んだチャネル(ラストクリック)に引っ張られやすい
この状態だと、改善の打ち手が「LP?広告?リマケ?」のようにブレやすく、社内説明も通りづらくなります。
この記事でできること(結論)
結論から言うと、この記事のSQLを使うと次ができます。
- CVしたユーザーだけを対象に
- 初回セッション〜最初のCVまでのセッションを
- 時系列(セッション順)で一覧化できる
つまり、CVに至るまでの「行動ログ(セッション履歴)」を作れます。
このログがあると、CVを“点”ではなく、「どのチャネルで認知され、どう再訪され、どの接触で決断されたか」という“過程”で語れるようになります。
このSQLで可視化できる行動データ
ここからは、SQLが「具体的に何を見えるようにするか」を整理します。
CVまでに何回・何日かかっているか
まず重要なのが、CVまでの「接触回数」と「検討期間」です。
- CVまでに何回のセッションがあったか(例:1回で即CV / 5回見てCV)
- 初回セッションから何日目にCVしたか(例:当日 / 3日後 / 10日後)
これが見えるだけで、改善の方向性が変わります。
即決が多いなら「初回のLP・訴求」が勝負になり、検討が長いなら「再訪設計」が勝負になります。
初回接触とCV接触のチャネルの違い
GA4の現場で一番揉めやすいのがここです。
- 初回は広告で入ってきたのに、CVはdirectだった
- 初回はSNS、CVは自然検索だった
ラストクリックで見ると「directが最強」に見えますが、実際は最初の接触がきっかけを作っているケースが多いです。
このSQLは、ユーザーごとにセッションを並べるので、初回接触〜CV接触までの流入の変化をそのまま追えます。
同日CVか、日跨ぎCVか
CVまでの時間は「日数」だけでなく、再訪の仕方も重要です。
- 同日に何回も行ったり来たりしてCVするタイプ
- 数日空けて再訪し、比較検討してCVするタイプ
この違いが見えると、施策の仮説が立てやすくなります。
同日型が多いなら「情報の迷子」や「比較の不足」、日跨ぎ型が多いなら「リマケや指名検索の設計」が論点になりがちです。
出力データの見方
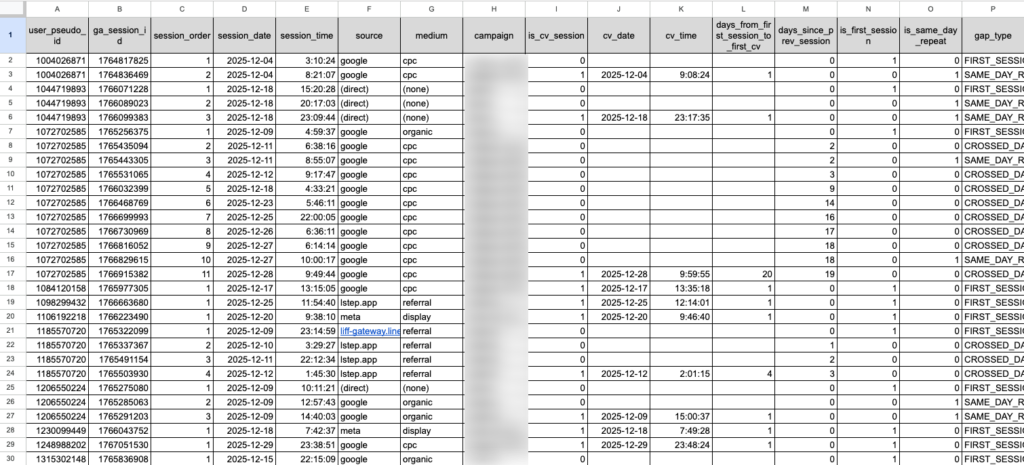
ここはこの記事の中で一番大事です。
SQLを動かせても「どこを見ればいいか」が曖昧だと、結局使われなくなります。
1行=1セッションという考え方
出力は基本的にこう捉えます。
- 1行=1セッション
- 同じユーザーの行が、時系列で並ぶ
- 最後のほうに CVセッション(is_cv_session=1) が出てくる
つまり「ユーザー別のセッション履歴表」です。
CVまでの接触回数の見方
見るのは session_order です。
- session_order = 1 が初回セッション
- CV行の session_order が大きいほど、CVまでに接触回数が多い
この数値が大きいユーザーが多いなら、
初回LPだけで決めるのは難しく、再訪時の情報設計が重要になりやすいです。
見るのは2つです。
- days_from_first_session:各セッションが初回から何日目か(初回=0)
- days_from_first_session_to_first_cv:CVまでの日数(CV行のみ、当日=1)
この2つがあることで、ユーザーの動きを
「初回→1日目→2日目→CV」のように、時間軸で整理できます。
再訪パターンの見方
見るのは gap_type です。
- FIRST_SESSION:初回
- SAME_DAY_REPEAT:同日再訪
- CROSSED_DAY:日跨ぎ再訪
この分類があると、CVまでのプロセスが“構造”になります。
例えば「同日再訪が多いのにCVまで時間がかかる」なら、どこかで迷っている可能性が高い、といった仮説が立てられます。
この分析からわかる、よくあるパターン
実務でよく出る典型パターンを2つに整理します。
初回接触でCVするケース
特徴は次の通りです。
- CV行の session_order が小さい(1〜2回程度)
- days_from_first_session_to_first_cv が短い(当日=1、または2日以内)
- 初回の source/medium/campaign がCV行と近いことも多い
このタイプが多い場合、改善の主戦場は「初回体験」です。
つまり、広告訴求とLPの整合、フォーム前の不安要素、比較のしやすさなどが効きます。
複数回接触してCVするケース
特徴は次の通りです。
- CV行の session_order が大きい(3回以上)
- CROSSED_DAY が混ざりやすい(比較検討の気配)
- 初回は広告、CVはdirect/organic、という流れが起きやすい
このタイプが多い場合、初回だけに投資しても伸びづらいです。
重要になるのは、再訪時に「迷いを減らす情報」が揃っているか、そして再訪を取りにいく設計があるかです。
実務での使いどころ
このSQLが刺さるのは、次のような場面です。
- 媒体評価の説明を強くしたい(ラストだけで語らない)
- CVの増減に対して、ユーザー行動の変化で説明したい
- LP改善・広告改善の議論で、「どっちが主因か」を切り分けたい
- 商材が「即決型か、検討型か」を、実データで掴みたい
特に「施策の優先順位」を決めるときに、
CVユーザーの行動履歴があると判断が速くなります。
そのまま使えるSQLテンプレート
ここからはコピペで使えるようにSQLを置きます。
技術解説よりも「動かして使う」ことを優先します。
案件ごとに編集する箇所
編集するのは基本的にこの3点です。
- 期間(params の start/end:YYYYMMDD)
- events_ テーブル参照先*(プロジェクト / データセット)
- CVイベント名(purchase / generate_lead / sign_up など)
SQLテンプレート全文
=====================================================================
✅ GA4(BigQuery Export)テンプレSQL:CVまでのセッション時系列(案件汎用)
【このSQLでできること】
・CVしたユーザーだけを対象に、初回セッション〜最初のCVまでのセッションを時系列で出力
・CVセッション行にのみ「初回→最初のCVまでの経過日数(当日=1)」を付与
・各セッションに「初回セッションから何日目か(初回=0)」を付与
・同日再訪 / 初回セッションを判別する補助列も付与
【あなたが編集する箇所(必須)】
1) params:期間(YYYYMMDD)
2) settings:events_* テーブル(プロジェクト/データセット)
3) settings:CVイベント名(例:purchase, generate_lead など)
===================================================================== */
WITH
/* =========================================================
✅ 設定(案件ごとにここだけ触るのが基本)
========================================================= */
settings AS (
SELECT
-- ✅【要編集】BigQueryのGA4 Export テーブル(events_*)の参照先
-- 例:`your-project.your_dataset.events_*`
'`YOUR_PROJECT.YOUR_DATASET.events_*`' AS events_table,
-- ✅【要編集】CVイベント名
-- 例:'purchase' / 'generate_lead' / 'sign_up' / 独自イベント名
'YOUR_CV_EVENT_NAME' AS cv_event_name
),
/* =========================================================
✅ 期間指定(通常は YYYYMMDD の8桁)
========================================================= */
params AS (
SELECT
'YYYYMMDD' AS start_suffix, -- ✅【要編集】開始日
'YYYYMMDD' AS end_suffix -- ✅【要編集】終了日
),
/* =========================================================
🎯 CVイベントを「ユーザー×セッション」で抽出
・同一セッション内で複数CVがあっても最初のCV時刻を採用
========================================================= */
cv_events AS (
SELECT
user_pseudo_id,
(SELECT ep.value.int_value
FROM UNNEST(event_params) ep
WHERE ep.key = 'ga_session_id') AS ga_session_id,
MIN(event_timestamp) AS cv_timestamp
FROM
-- ✅ settings.events_table を使うために EXECUTE IMMEDIATE は不要な構成にしています
-- 👉 参照先は下の FROM を案件ごとに直接書き換えてください
`YOUR_PROJECT.YOUR_DATASET.events_*`
WHERE
_TABLE_SUFFIX BETWEEN (SELECT start_suffix FROM params)
AND (SELECT end_suffix FROM params)
AND event_name = (SELECT cv_event_name FROM settings)
GROUP BY
user_pseudo_id,
ga_session_id
),
/* =========================================================
✅ CVしたユーザーだけに絞る(パフォーマンス改善)
========================================================= */
cv_users AS (
SELECT DISTINCT user_pseudo_id
FROM cv_events
),
/* =========================================================
📌 session_start から「セッション単位の流入」を抽出
【流入の優先順位】
1) session_traffic_source_last_click(セッション最終クリックの流入)
2) collected_traffic_source(手動/UTM等)
3) event_params(source/medium/campaignが入ってる場合)
4) traffic_source(獲得寄りでセッション値じゃないことがあるため最終手段)
========================================================= */
user_sessions AS (
SELECT
e.user_pseudo_id,
(SELECT ep.value.int_value
FROM UNNEST(e.event_params) ep
WHERE ep.key = 'ga_session_id') AS ga_session_id,
e.event_timestamp AS session_start_timestamp,
-- source
COALESCE(
e.session_traffic_source_last_click.cross_channel_campaign.source,
e.collected_traffic_source.manual_source,
(SELECT ep.value.string_value FROM UNNEST(e.event_params) ep WHERE ep.key = 'source'),
e.traffic_source.source
) AS source,
-- medium
COALESCE(
e.session_traffic_source_last_click.cross_channel_campaign.medium,
e.collected_traffic_source.manual_medium,
(SELECT ep.value.string_value FROM UNNEST(e.event_params) ep WHERE ep.key = 'medium'),
e.traffic_source.medium
) AS medium,
-- campaign
COALESCE(
e.session_traffic_source_last_click.cross_channel_campaign.campaign_name,
e.collected_traffic_source.manual_campaign_name,
(SELECT ep.value.string_value FROM UNNEST(e.event_params) ep WHERE ep.key = 'campaign'),
e.traffic_source.name
) AS campaign
FROM
`YOUR_PROJECT.YOUR_DATASET.events_*` e
WHERE
e._TABLE_SUFFIX BETWEEN (SELECT start_suffix FROM params)
AND (SELECT end_suffix FROM params)
AND e.event_name = 'session_start'
AND e.user_pseudo_id IN (SELECT user_pseudo_id FROM cv_users)
),
/* =========================================================
🧩 セッションにCV情報を付与 + セッション順序 + 前回セッション時刻
・ユーザー内で時系列に並べるため session_order を付与
========================================================= */
cv_sessions_with_rank AS (
SELECT
us.*,
CASE WHEN cv.ga_session_id IS NOT NULL THEN 1 ELSE 0 END AS is_cv_session,
cv.cv_timestamp,
ROW_NUMBER() OVER (
PARTITION BY us.user_pseudo_id
ORDER BY us.session_start_timestamp
) AS session_order,
LAG(us.session_start_timestamp) OVER (
PARTITION BY us.user_pseudo_id
ORDER BY us.session_start_timestamp
) AS prev_session_start_timestamp
FROM
user_sessions us
LEFT JOIN
cv_events cv
ON us.user_pseudo_id = cv.user_pseudo_id
AND us.ga_session_id = cv.ga_session_id
),
/* =========================================================
🎯 各ユーザーの「最初のCV時刻」を確定
========================================================= */
first_cv_per_user AS (
SELECT
user_pseudo_id,
MIN(cv_timestamp) AS first_cv_timestamp
FROM
cv_events
GROUP BY
user_pseudo_id
),
/* =========================================================
🎯 各ユーザーの「初回セッション開始時刻」を確定
========================================================= */
first_session_per_user AS (
SELECT
user_pseudo_id,
MIN(session_start_timestamp) AS first_session_start_timestamp
FROM
user_sessions
GROUP BY
user_pseudo_id
),
/* =========================================================
📦 出力用ファクトテーブル(最初のCVまで)
・最初のCV以前(CVセッション含む)のセッションのみ残す
・days_from_first_session_to_first_cv は「当日を1」としてカウント(CV行のみ)
・days_from_first_session は「初回セッションから何日目か」(初回=0)
========================================================= */
session_data AS (
SELECT
csr.user_pseudo_id,
csr.ga_session_id,
csr.session_order,
FORMAT_TIMESTAMP('%F', TIMESTAMP_MICROS(csr.session_start_timestamp)) AS session_date,
FORMAT_TIMESTAMP('%T', TIMESTAMP_MICROS(csr.session_start_timestamp)) AS session_time,
csr.source,
csr.medium,
csr.campaign,
csr.is_cv_session,
FORMAT_TIMESTAMP('%F', TIMESTAMP_MICROS(csr.cv_timestamp)) AS cv_date,
FORMAT_TIMESTAMP('%T', TIMESTAMP_MICROS(csr.cv_timestamp)) AS cv_time,
-- ✅ 初回セッション → 最初のCV までにかかった日数(当日=1、CV行のみ。それ以外NULL)
CASE
WHEN csr.is_cv_session = 1 THEN
DATE_DIFF(
DATE(TIMESTAMP_MICROS(fcv.first_cv_timestamp)),
DATE(TIMESTAMP_MICROS(fsu.first_session_start_timestamp)),
DAY
) + 1
ELSE NULL
END AS days_from_first_session_to_first_cv,
-- ✅ 初回セッションから何日目か(初回=0)
DATE_DIFF(
DATE(TIMESTAMP_MICROS(csr.session_start_timestamp)),
DATE(TIMESTAMP_MICROS(fsu.first_session_start_timestamp)),
DAY
) AS days_from_first_session,
-- ✅ 補助列:初回 or 同日再訪
CASE WHEN csr.session_order = 1 THEN 1 ELSE 0 END AS is_first_session,
CASE
WHEN csr.session_order = 1 THEN 0
WHEN DATE(TIMESTAMP_MICROS(csr.session_start_timestamp))
= DATE(TIMESTAMP_MICROS(csr.prev_session_start_timestamp))
THEN 1
ELSE 0
END AS is_same_day_repeat,
CASE
WHEN csr.session_order = 1 THEN 'FIRST_SESSION'
WHEN DATE(TIMESTAMP_MICROS(csr.session_start_timestamp))
= DATE(TIMESTAMP_MICROS(csr.prev_session_start_timestamp))
THEN 'SAME_DAY_REPEAT'
ELSE 'CROSSED_DAY'
END AS gap_type
FROM
cv_sessions_with_rank csr
JOIN
first_cv_per_user fcv
USING (user_pseudo_id)
JOIN
first_session_per_user fsu
USING (user_pseudo_id)
WHERE
csr.session_start_timestamp <= fcv.first_cv_timestamp
AND csr.session_order <= 300
)
-- =========================================================
-- ✅ 最終出力
-- =========================================================
SELECT
*
FROM
session_data
ORDER BY
user_pseudo_id,
session_order;
まとめ|CVは「過程」で見る
CVの増減を説明するには、「最後に踏んだチャネル」だけでは情報が足りません。
初回接触からCVまでのセッション履歴が見えると、認知・比較・再訪・決断の流れを、データで語れるようになります。